- Published on
SurrealDB - the ultimate database
- Authors

- Name
- Alex Zurka
Paradigms
There are several paradigms of databases:
- Key-Value:
Stores data in key-value representation, where the key points to a specific value.
Useful for storing API responses in memory, which makes websites much faster.
Popular choices: Redis, Memcached - Relational:
The most common type of database, where the database has a predefined schema, (schema-based)
which ensures data consistency, and simplifies querying.
Not designed to be scaled horizontally (across multiple machines), which makes it
more difficult to scale, but easier to set up.
Popular choices: Postgresql, MySQL, MSSQL - Wide Column:
NoSQL type of database, that allows querying columns based on the key.
Does not require a predefined schema, which provides schema flexibility.
New columns can be added without altering the entire schema.
Designed to be distributed, and hence, scalable horizontally.
Popular choices: Cassandra, Apache HBASE - Document Oriented:
Can be considered as a subclass of key-value storage.
With the key difference to key-value being the availability for the DB to be optimized based on a metadata, where in key-value data is opaque to the DB.
Stores data in self-contained documents with a flexible schema, documents can be JSON or XML.
Each document can be accessed with a key that is either a string, a URI, or a path.
Popular choices: MongoDB, CouchDB, DynamoDB (Proprietary) - Graph:
Perfect for interconnected data, where each object in database is linked to another.
Relationships between objects are prioritized, and hence optimized for querying with a single query. Each object is represented as a node, and connection with other nodes as an edge.
Queried data is intuitively visualized.
Popular choices: Dgraph, Neo4j - Search:
Optimized for full-text search, search databases (or search engines), are used for retrieval of text based data.
Popular choices: Elaticsearch - Time Series:
Focused on storing and serving time based data, through pairs of associated time and value.
Very efficient for data with a lot of timestamps, like analytics platform, industrial IoT, etc Popular choices: TimescaleDB, InfluxDB, Prometheus
SurrealDB
With its engine written on Rust, SurrealDB designed to be efficient, and be either embedded DB, or a part of a distributed cluster.
Can be used as both - schemafull, providing sustainability when structured data is required, or schemaless, providing flexibility, when unstructured data is expected.
Getting started
The recommended approach to run SurrealDB locally will be using Docker:
docker volume create db-data
docker run --rm --pull always -p 8000:8000 --user root --pass root -v db-data:/db-data surrealdb/surrealdb:latest-dev start file:/db-data/data.db
Here the reason why we created a volume db-data is not only to persist data across container restarts, but also to ensure that SurrealDB container will not accidentally delete it when you restart/stop the container. Also we used -dev tag to avoid permissions issues, that can happen with production container of SurrealDB.
Executing queries
You can do so by visiting web app https://surrealist.app, or by installing the latest version of it from Github https://github.com/surrealdb/surrealist
Next you can create a record with
create command: As you can see, SurrealDB supports json-like format of inserting data, as well as some useful built-in functions.
As you can see, SurrealDB supports json-like format of inserting data, as well as some useful built-in functions.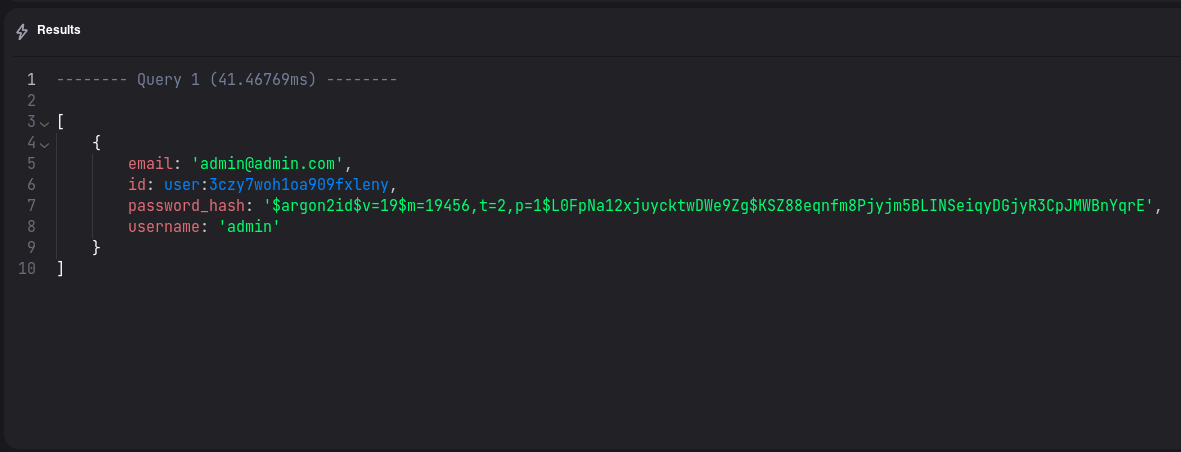 In response we will get newly created object, along with time spent for executing query, and
In response we will get newly created object, along with time spent for executing query, and id.ids have a special structure in SurrealDB: the first part is a name of the table, and second is randomly generated record identifier.That way, each
id represents unique sequence, allowing for easy query in distributed clusters.However, its still possible to use numeric identifiers, if you would like.
For instance:
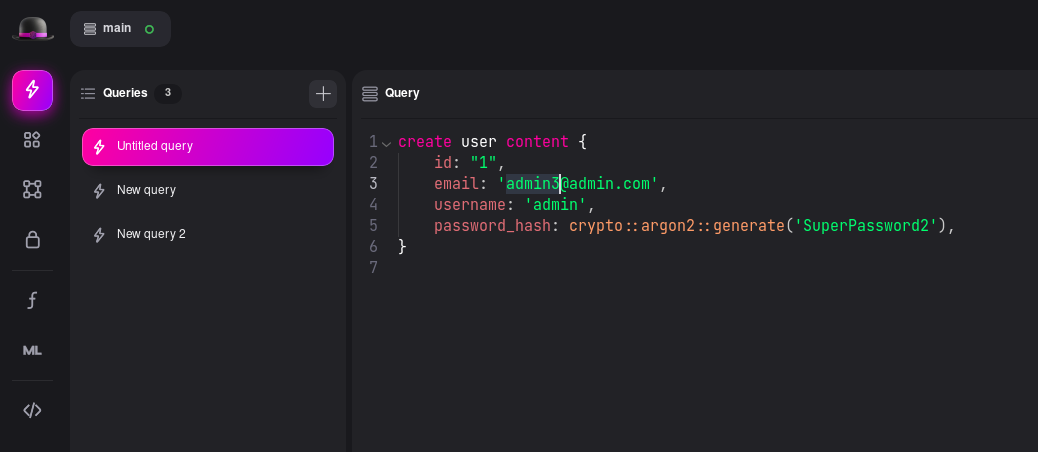 FYI SurrealDB doesn't support auto-incrementing like traditional DBs.
FYI SurrealDB doesn't support auto-incrementing like traditional DBs.You can also use
ULID (for time based sorting, and better collision resistance): 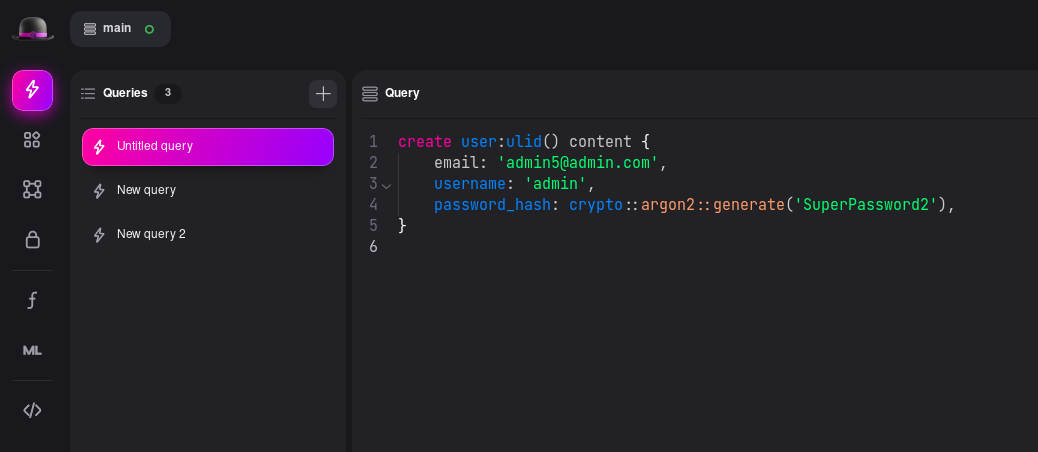
Schemafull
schemaless approach, that doesn't guarantee data consistency.Thankfully, SurrealDB supports defining schema as well, so lets create some schema:
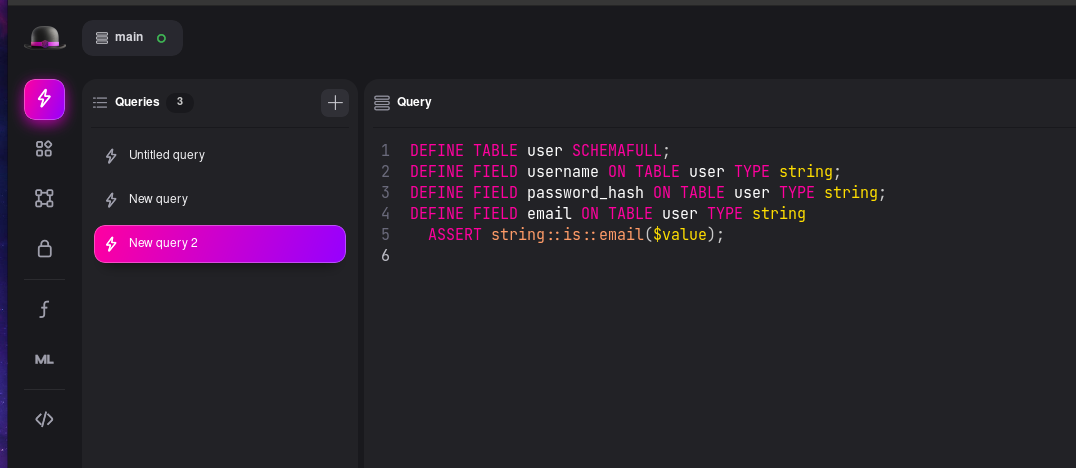 And now, if we try to execute the query while omitting the username, we will get an error:
And now, if we try to execute the query while omitting the username, we will get an error: 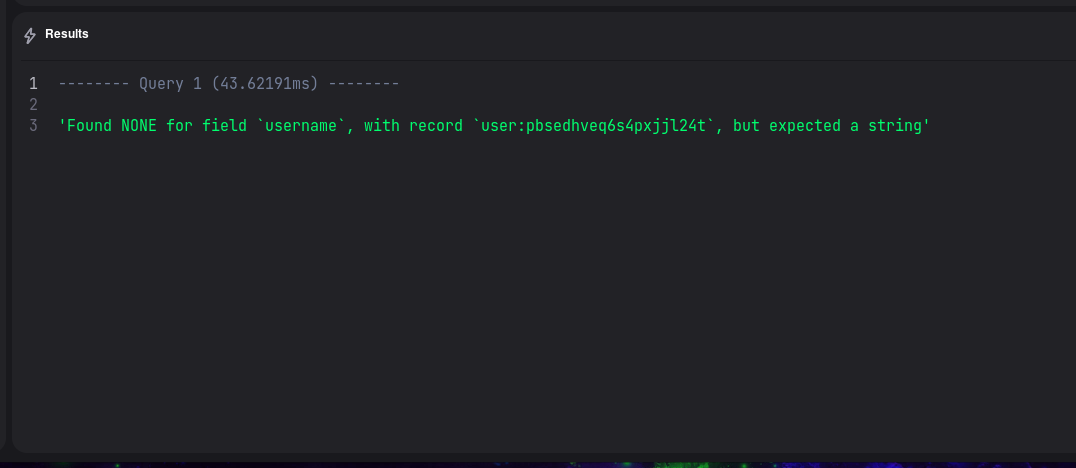
Graph
the most convenient way will be using graph edges.
In SurrealDB its done via
relate and arrows keywords.Lets create some edges !
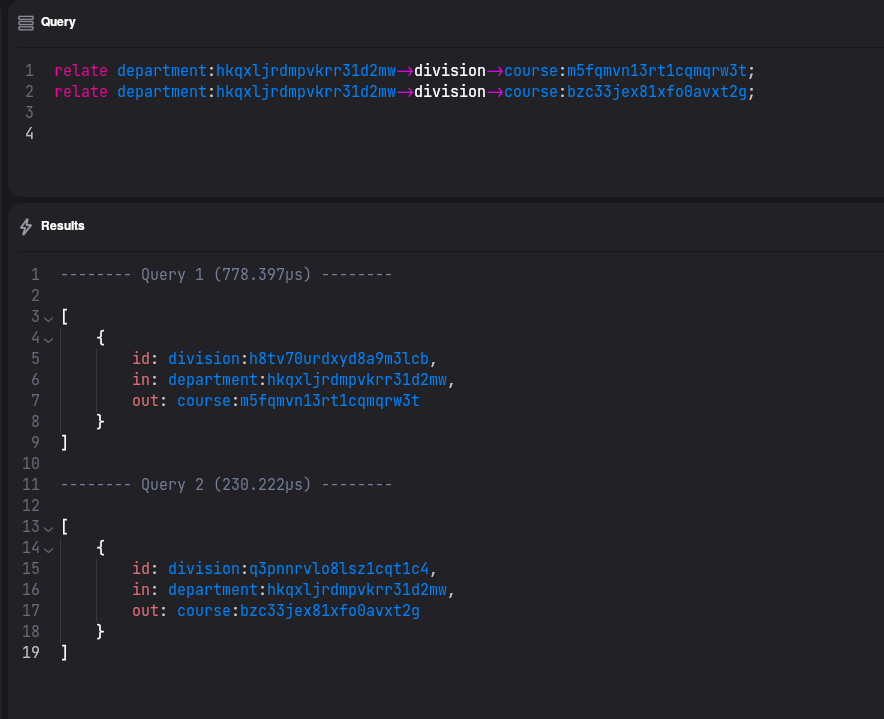 Now if we want to display all courses, that belongs to our department, we can query as follows:
Now if we want to display all courses, that belongs to our department, we can query as follows: 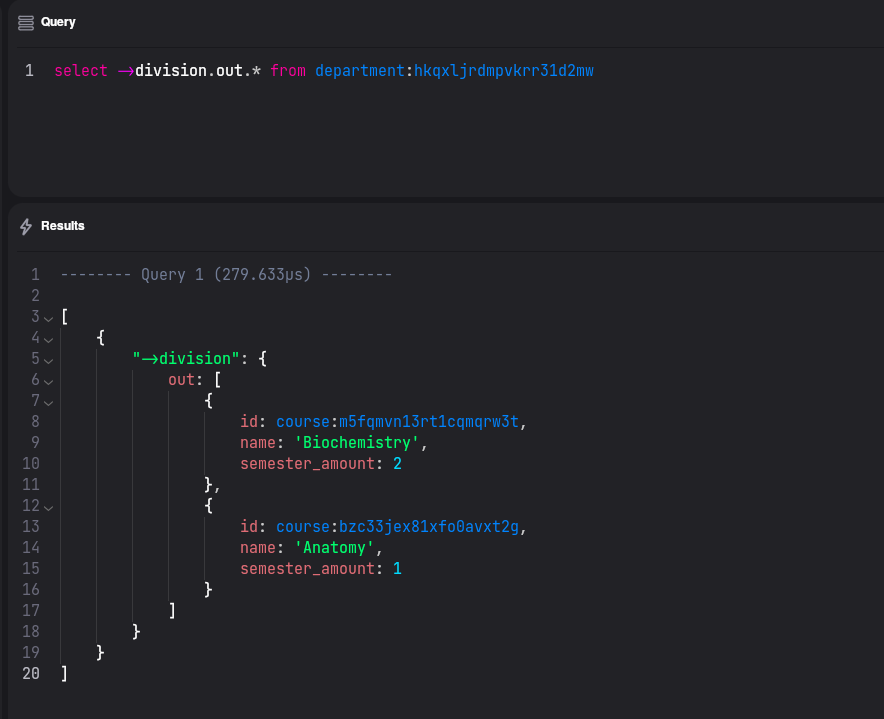
Available tools
 And the number of available tools and SDK is growing rapidly.
And the number of available tools and SDK is growing rapidly.Conclusion
SurrealDB is undoubtedly a modern, feature-rich, and competitive alternative to well-established relational databases.
With its flexibility to fit almost any business requirements, it unlocks new potential for developers and data engineers alike, positioning SurrealDB as a valuable asset in the evolving data landscape.